XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 05 abril 2025

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
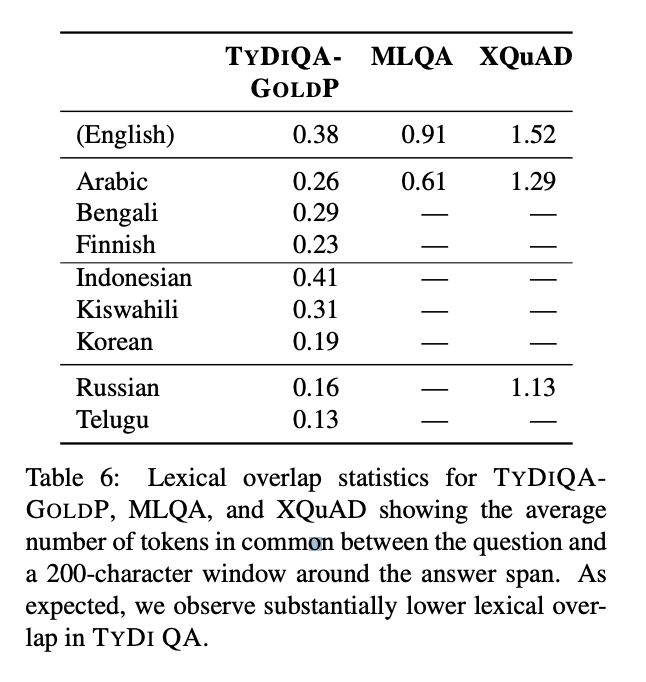
TyDiQA-GoldP Dataset

LSP Dataset - Machine Learning Datasets
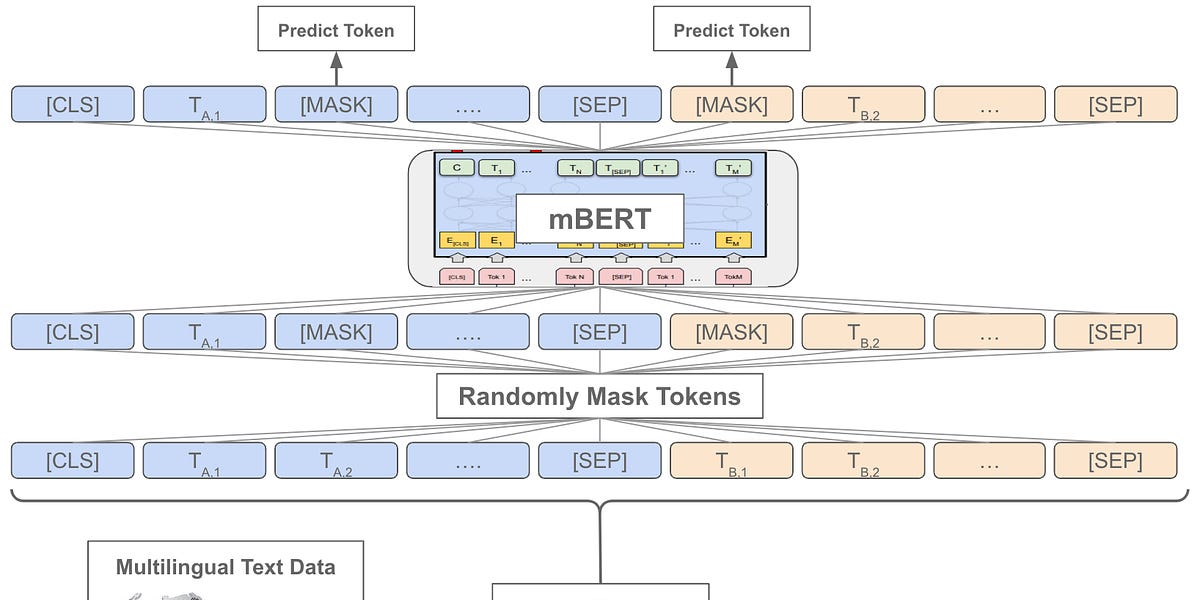
Many Languages, One Deep Learning Model

Automatic Spanish Translation of SQuAD Dataset for Multi-lingual

MLQA Dataset Papers With Code

Papers + Code - MIT-IBM Watson AI Lab
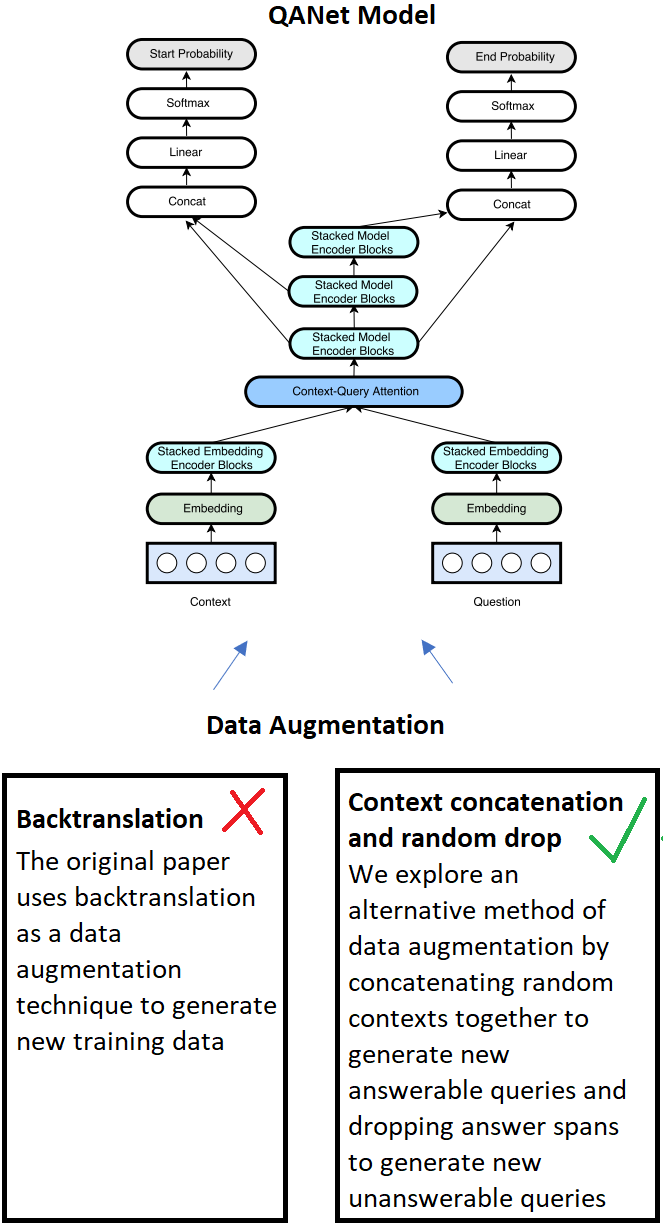
image171.png

SQuAD2.0 Benchmark (Question Answering)
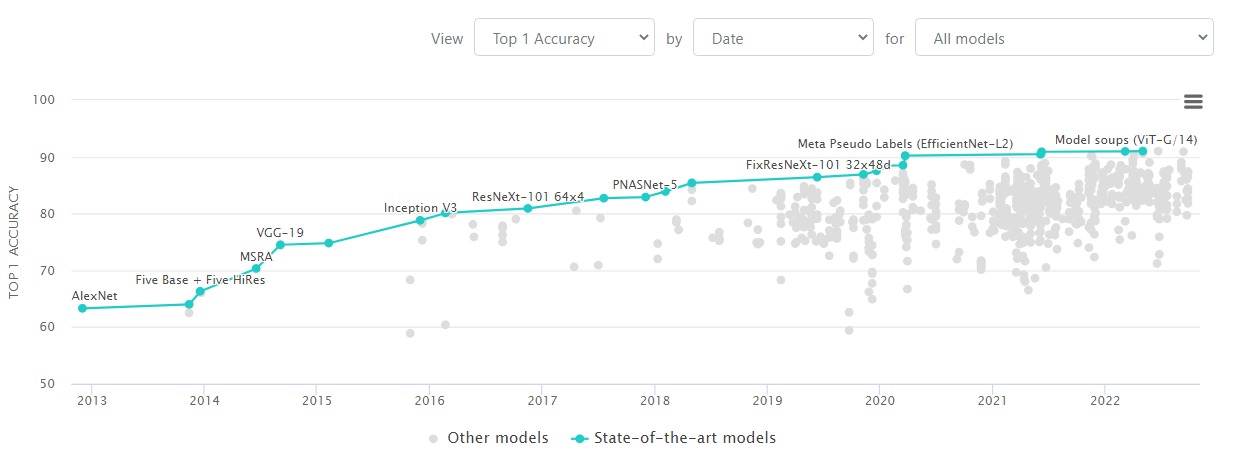
An Introduction to Papers With Code: What It is And How to Use It

SQuAD model sentence relation and deep semantics error

ACL Best Paper: Tricky Stanford DataSet Adds Questions That Don't

Sensitivity to parameter choices on the Kazer et al.⁶ dataset and
Recomendado para você
-
 I.C. Engines MCQ Questions PDF by Deepu Kumar - Issuu05 abril 2025
I.C. Engines MCQ Questions PDF by Deepu Kumar - Issuu05 abril 2025 -
 Pin on Engineering05 abril 2025
Pin on Engineering05 abril 2025 -
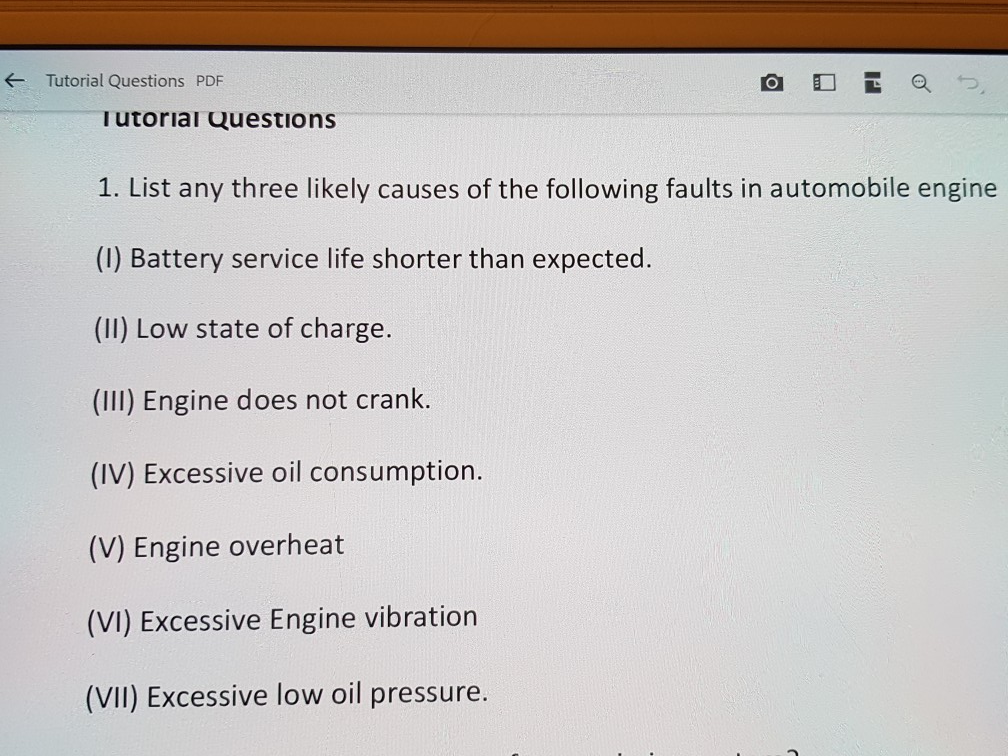 Solved ← Tutorial Questions PDF utoriai Questions 1. List05 abril 2025
Solved ← Tutorial Questions PDF utoriai Questions 1. List05 abril 2025 -
 SOLUTION: Engine system 500 questions converted pdf - Studypool05 abril 2025
SOLUTION: Engine system 500 questions converted pdf - Studypool05 abril 2025 -
AICE-OQ - Unit-1, PDF, Fuel Injection05 abril 2025
-
 Ic engine ies gate ias 20 years question and answers05 abril 2025
Ic engine ies gate ias 20 years question and answers05 abril 2025 -
 SEM Exam - 50 Questions with answers05 abril 2025
SEM Exam - 50 Questions with answers05 abril 2025 -
 ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score05 abril 2025
ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score05 abril 2025 -
 Top 30 Mobile Testing Interview Questions & Answers for 202305 abril 2025
Top 30 Mobile Testing Interview Questions & Answers for 202305 abril 2025 -
 Internal Combustion Engines: Expository Reading by Creative Curricula05 abril 2025
Internal Combustion Engines: Expository Reading by Creative Curricula05 abril 2025

você pode gostar
-
 O Último Xeque-Mate05 abril 2025
O Último Xeque-Mate05 abril 2025 -
 Emancipação da América Espanhola - 8º ano by karyne Velasco05 abril 2025
Emancipação da América Espanhola - 8º ano by karyne Velasco05 abril 2025 -
 Genshin Impact: Yelan guide — Best weapons, artifacts, and talents05 abril 2025
Genshin Impact: Yelan guide — Best weapons, artifacts, and talents05 abril 2025 -
 Monster Hunter Rise comes to Xbox, PlayStation minus cross-saves05 abril 2025
Monster Hunter Rise comes to Xbox, PlayStation minus cross-saves05 abril 2025 -
 A Confusão de Bobby Fischer no Interzonal de 196705 abril 2025
A Confusão de Bobby Fischer no Interzonal de 196705 abril 2025 -
 11cm Rainbow Friends Roblox Figures Pvc Decorative Collectibles05 abril 2025
11cm Rainbow Friends Roblox Figures Pvc Decorative Collectibles05 abril 2025 -
 Batman: Return to Arkham Officially Revealed, Coming This July05 abril 2025
Batman: Return to Arkham Officially Revealed, Coming This July05 abril 2025 -
 U. Cluj Liveergebnisse, Resultate, Spielpaarungen, U. Cluj - Otelul live05 abril 2025
U. Cluj Liveergebnisse, Resultate, Spielpaarungen, U. Cluj - Otelul live05 abril 2025 -
 M3GAN: Boneca de novo longa de terror vira fenômeno pop, com05 abril 2025
M3GAN: Boneca de novo longa de terror vira fenômeno pop, com05 abril 2025 -
 The Last Kingdom: News & Reviews05 abril 2025
The Last Kingdom: News & Reviews05 abril 2025