A Neural Parametric Singing Synthesizer – arXiv Vanity
Por um escritor misterioso
Last updated 10 abril 2025

We present a new model for singing synthesis based on a modified version of the WaveNet architecture. Instead of modeling raw waveform, we model features produced by a parametric vocoder that separates the influence of pitch and timbre. This allows conveniently modifying pitch to match any target melody, facilitates training on more modest dataset sizes, and significantly reduces training and generation times. Our model makes frame-wise predictions using mixture density outputs rather than categorical outputs in order to reduce the required parameter count. As we found overfitting to be an issue with the relatively small datasets used in our experiments, we propose a method to regularize the model and make the autoregressive generation process more robust to prediction errors. Using a simple multi-stream architecture, harmonic, aperiodic and voiced/unvoiced components can all be predicted in a coherent manner. We compare our method to existing parametric statistical and state-of-the-art concatenative methods using quantitative metrics and a listening test. While naive implementations of the autoregressive generation algorithm tend to be inefficient, using a smart algorithm we can greatly speed up the process and obtain a system that’s competitive in both speed and quality.

Singing voice synthesis based on frame-level sequence-to-sequence

Audiovisual Speech Synthesis using Tacotron2 – arXiv Vanity

WGANSing: A Multi-Voice Singing Voice Synthesizer Based on the

Conditioning Deep Generative Raw Audio Models for Structured
A Neural Parametric Singing Synthesizer – arXiv Vanity

hf0: A hybrid pitch extraction method for multimodal voice – arXiv

A Tutorial on Deep Learning for Music Information Retrieval

A Tutorial on Deep Learning for Music Information Retrieval

Synthesizing Audio with Generative Adversarial Networks – arXiv Vanity
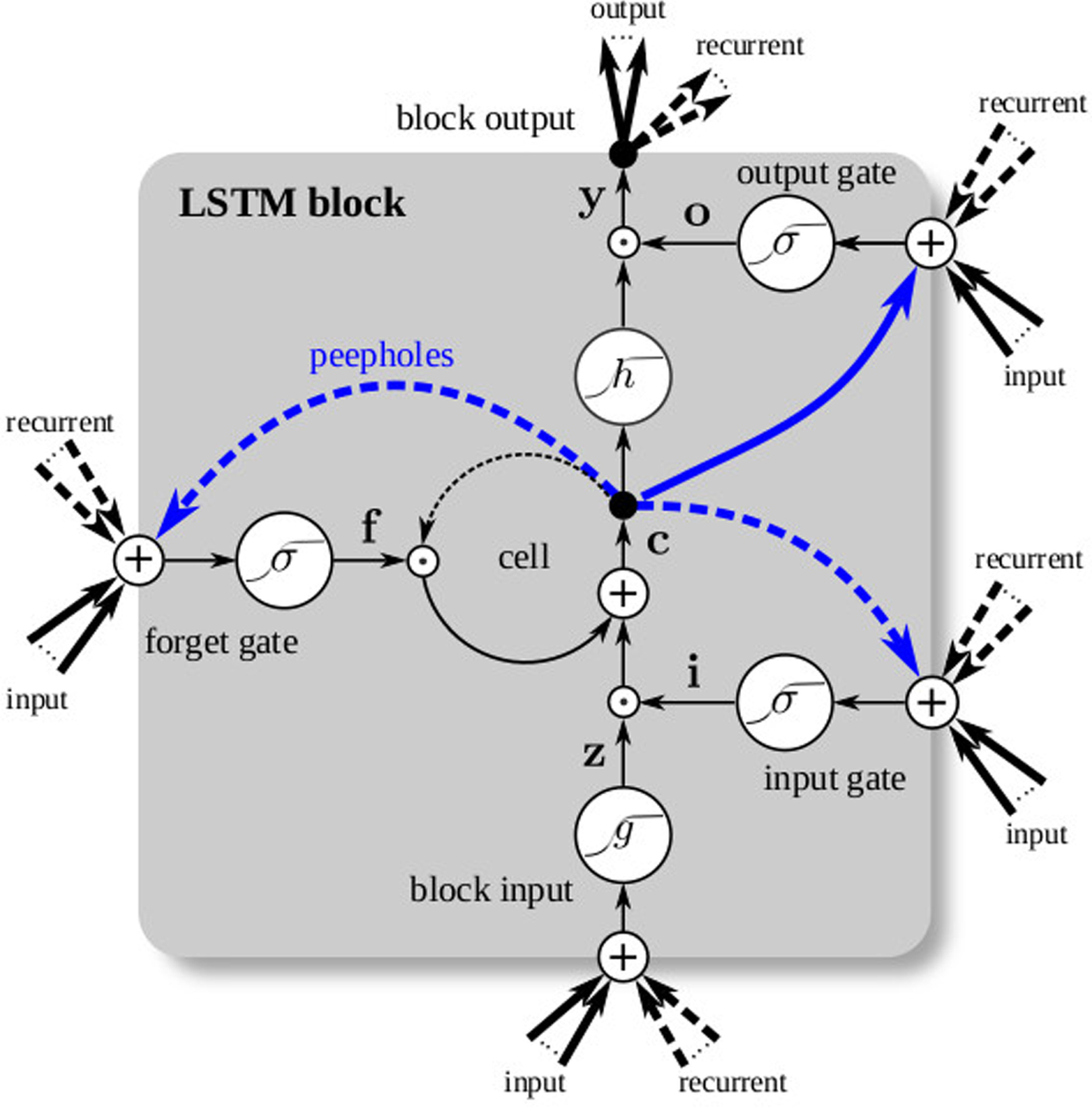
The artificial intelligence renaissance: deep learning and the

DiffSinger: Singing Voice Synthesis via Shallow Diffusion

HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis
Recomendado para você
-
 Input AC 100-240V Output 5V DC 3A Power Supply Adapter10 abril 2025
Input AC 100-240V Output 5V DC 3A Power Supply Adapter10 abril 2025 -
 singing machine power cord Adaptador de AC/DC para la máquina de10 abril 2025
singing machine power cord Adaptador de AC/DC para la máquina de10 abril 2025 -
 KRK Generation 4 Rokit RP5 G4 5 Powered Near-Field Studio Monitor Speakers Package10 abril 2025
KRK Generation 4 Rokit RP5 G4 5 Powered Near-Field Studio Monitor Speakers Package10 abril 2025 -
 JBL Partybox 310 Portable party speaker with dazzling lights and10 abril 2025
JBL Partybox 310 Portable party speaker with dazzling lights and10 abril 2025 -
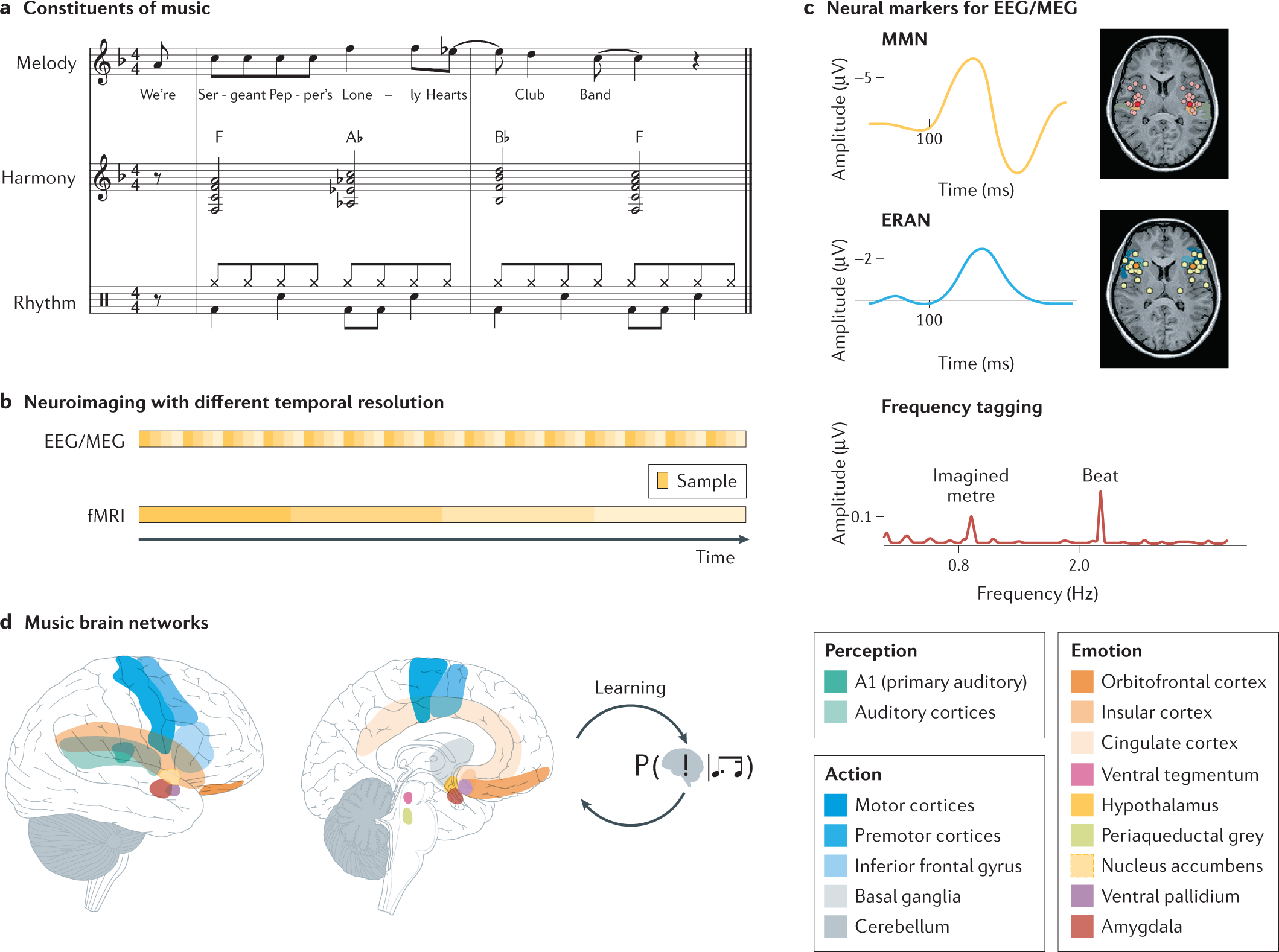 Music in the brain Nature Reviews Neuroscience10 abril 2025
Music in the brain Nature Reviews Neuroscience10 abril 2025 -
 Promotional Input 100-240v-50/60hz 0.3a Output 12v 1a Eu Ac Dc Power Supply Adapter - Buy Ac Adapter,Power Supply Adapter,Ac Dc Adapter Product on10 abril 2025
Promotional Input 100-240v-50/60hz 0.3a Output 12v 1a Eu Ac Dc Power Supply Adapter - Buy Ac Adapter,Power Supply Adapter,Ac Dc Adapter Product on10 abril 2025 -
 Mytek Brooklyn Bridge II ROON10 abril 2025
Mytek Brooklyn Bridge II ROON10 abril 2025 -
 JBL PartyBox 200 Portable Bluetooth party speaker with light effects10 abril 2025
JBL PartyBox 200 Portable Bluetooth party speaker with light effects10 abril 2025 -
Just Dance 2023 Ultimate Edition - Xbox (digital) : Target10 abril 2025
-
 SoundStage! Simplifi - Bluesound10 abril 2025
SoundStage! Simplifi - Bluesound10 abril 2025

você pode gostar
-
 Assassin's Creed Mirage' Release Date Trailer10 abril 2025
Assassin's Creed Mirage' Release Date Trailer10 abril 2025 -
 Ant-Man And The Wasp' Box Office Flying To $85 Million-$95 Million10 abril 2025
Ant-Man And The Wasp' Box Office Flying To $85 Million-$95 Million10 abril 2025 -
 8 regras desconhecidas do futebol americano - Shotgun10 abril 2025
8 regras desconhecidas do futebol americano - Shotgun10 abril 2025 -
 Jogos Online Wx Shoot Strike Army Commando shooting games Best10 abril 2025
Jogos Online Wx Shoot Strike Army Commando shooting games Best10 abril 2025 -
 How to Redeem Roblox Gift Card: A Step-By-Step Guide10 abril 2025
How to Redeem Roblox Gift Card: A Step-By-Step Guide10 abril 2025 -
 JOGO DE BARALHO CONVENCIONAL10 abril 2025
JOGO DE BARALHO CONVENCIONAL10 abril 2025 -
 You gotta believe! PaRappa the Rapper 2 is coming to PlayStation 410 abril 2025
You gotta believe! PaRappa the Rapper 2 is coming to PlayStation 410 abril 2025 -
 Clannad: After Story - Complete Anime Collection (Brand New 4 DVD10 abril 2025
Clannad: After Story - Complete Anime Collection (Brand New 4 DVD10 abril 2025 -
 Laser Games Tignieu, France - LaserBlast10 abril 2025
Laser Games Tignieu, France - LaserBlast10 abril 2025 -
 Tudo sobre Códigos, Resgates e Verificado no Free Fire - PS Verso10 abril 2025
Tudo sobre Códigos, Resgates e Verificado no Free Fire - PS Verso10 abril 2025