Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings
Por um escritor misterioso
Last updated 11 abril 2025
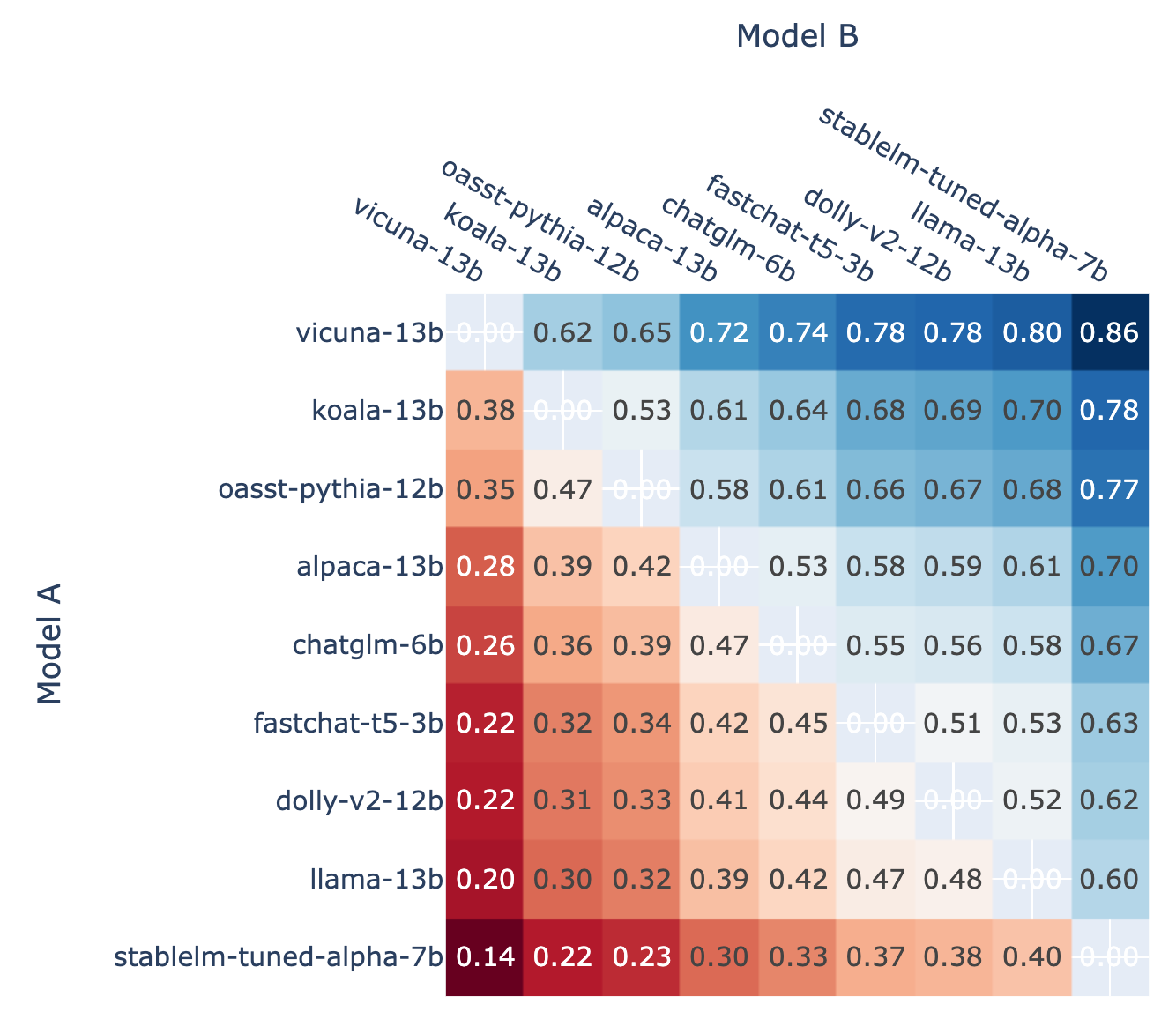
lt;p>We present Chatbot Arena, a benchmark platform for large language models (LLMs) that features anonymous, randomized battles in a crowdsourced manner. In t

Tracking through Containers and Occluders in the Wild- Meet TCOW: An AI Model that can Segment Objects in Videos with a Notion of Object Permanence - MarkTechPost
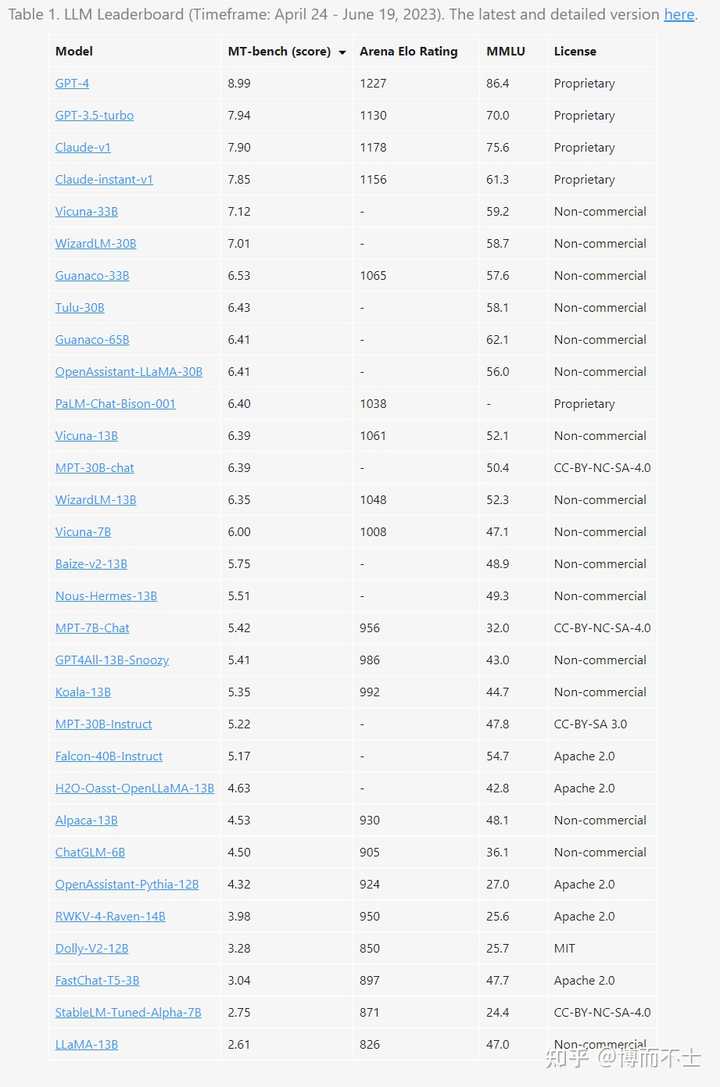
目前大语言模型的评测基准有哪些? - 博而不士的回答- 知乎

Chatbot showdown: ChatGPT, Google Bard, and Bing Chat put to a real-world test

PDF) PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization
main page · Issue #1 · shm007g/LLaMA-Cult-and-More · GitHub

Knowledge Zone AI and LLM Benchmarks
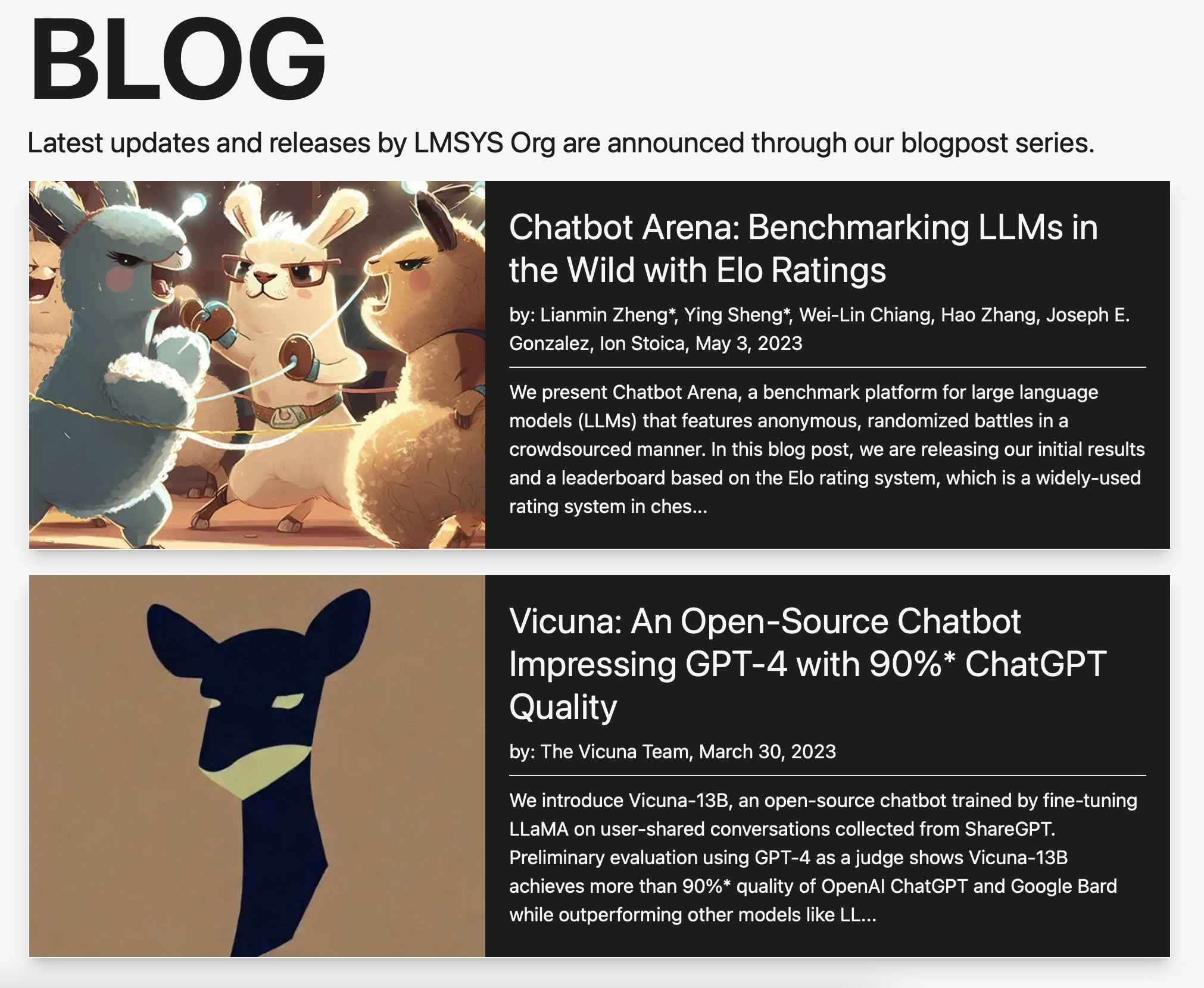
小羊驼Vicuna团队新作:Chatbot Arena——实际场景用Elo rating对LLM 进行基准测试- 智源社区

Chatbot Arena (聊天机器人竞技场) (含英文原文):使用Elo 评级对LLM进行基准测试-- 总篇- 知乎

PDF) LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
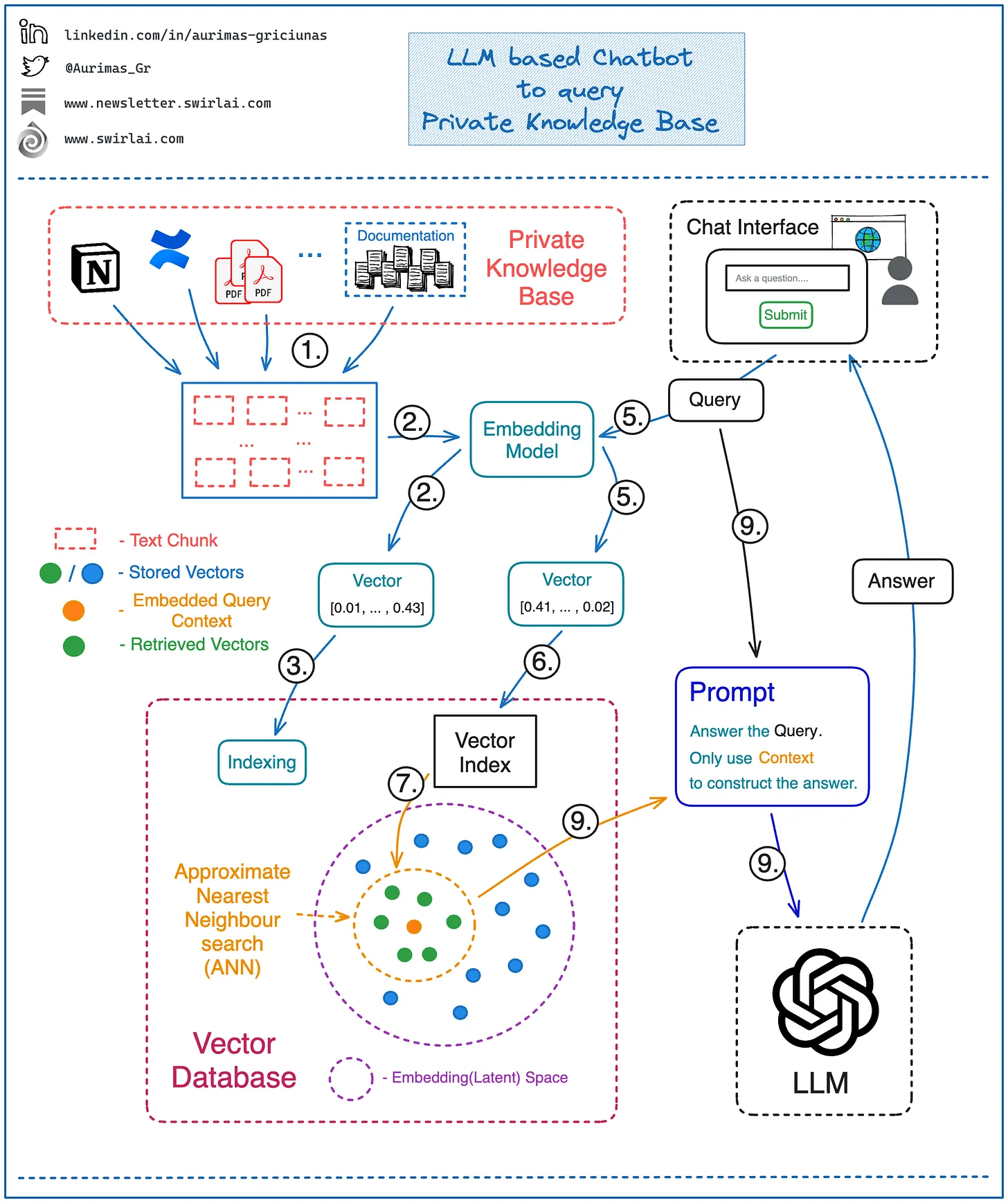
Vinija's Notes • Primers • Overview of Large Language Models
Recomendado para você
-
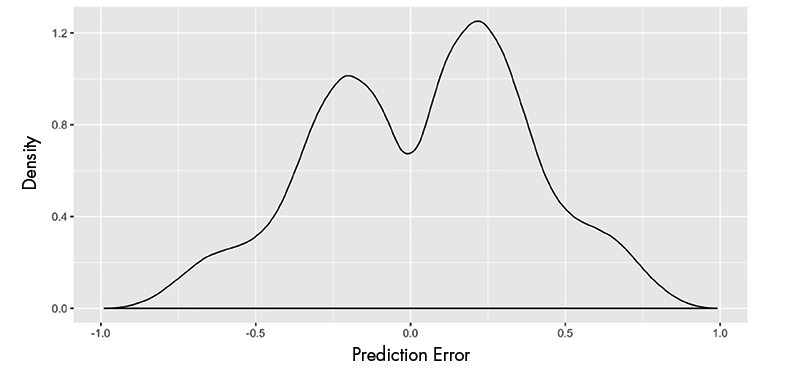 Statistical Analysis of the Elo Rating System in Chess11 abril 2025
Statistical Analysis of the Elo Rating System in Chess11 abril 2025 -
 Puzzles to test your chess elo( Just for fun!)11 abril 2025
Puzzles to test your chess elo( Just for fun!)11 abril 2025 -
 The Effect of Chess on Standardized Test Score Gains - David I. Poston, Kathryn K. Vandenkieboom, 201911 abril 2025
The Effect of Chess on Standardized Test Score Gains - David I. Poston, Kathryn K. Vandenkieboom, 201911 abril 2025 -
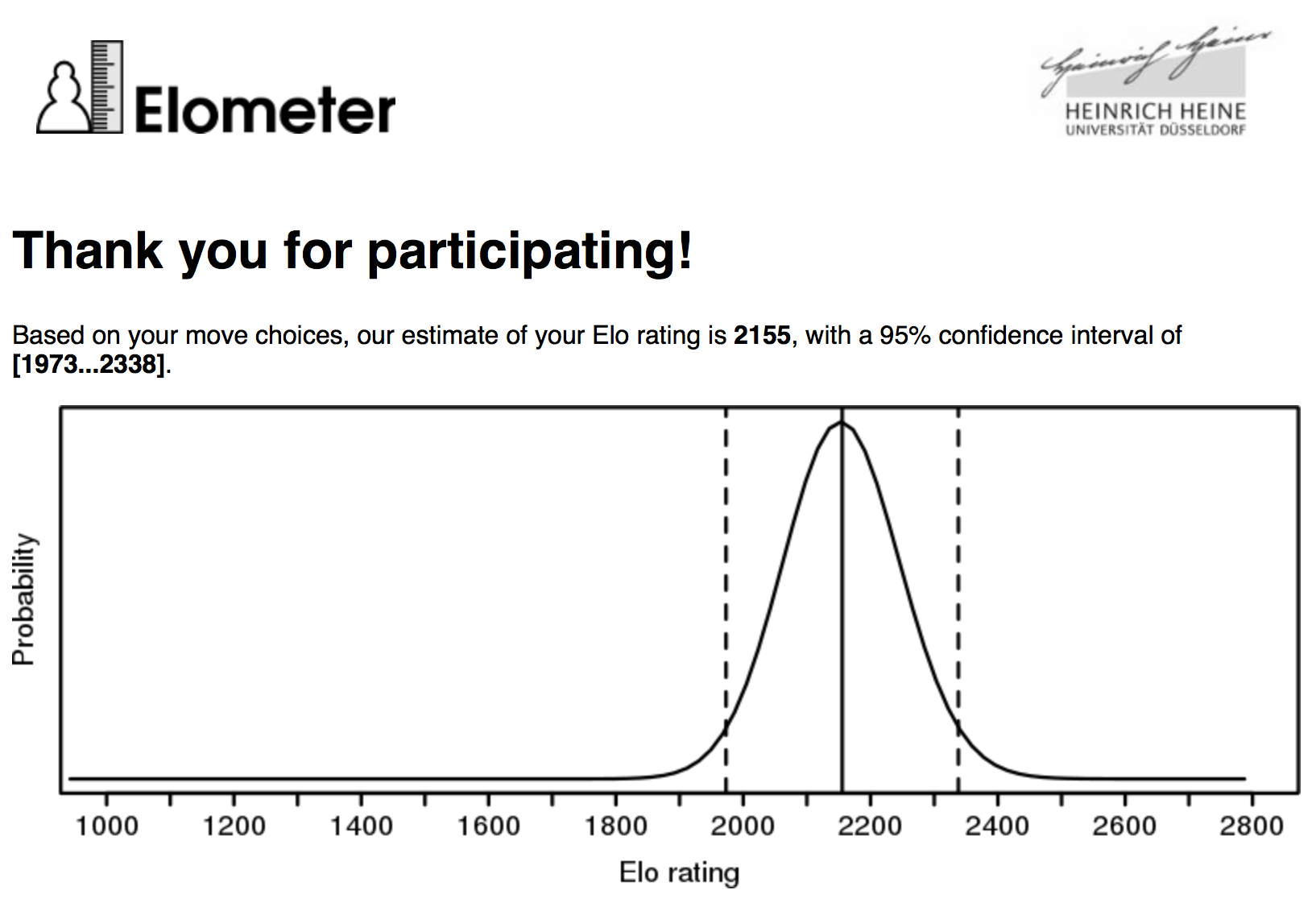 Find your REAL ELO rating: ELOMETER.NET then post here the results - Chess Forums - Page 711 abril 2025
Find your REAL ELO rating: ELOMETER.NET then post here the results - Chess Forums - Page 711 abril 2025 -
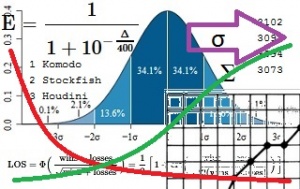 Match Statistics - Chessprogramming wiki11 abril 2025
Match Statistics - Chessprogramming wiki11 abril 2025 -
GitHub - fsmosca/STS-Rating: A method to rate chess engines using STS test suite.11 abril 2025
-
 Rating Sports Teams — Elo vs. Win-Loss, by Blake Atkinson11 abril 2025
Rating Sports Teams — Elo vs. Win-Loss, by Blake Atkinson11 abril 2025 -
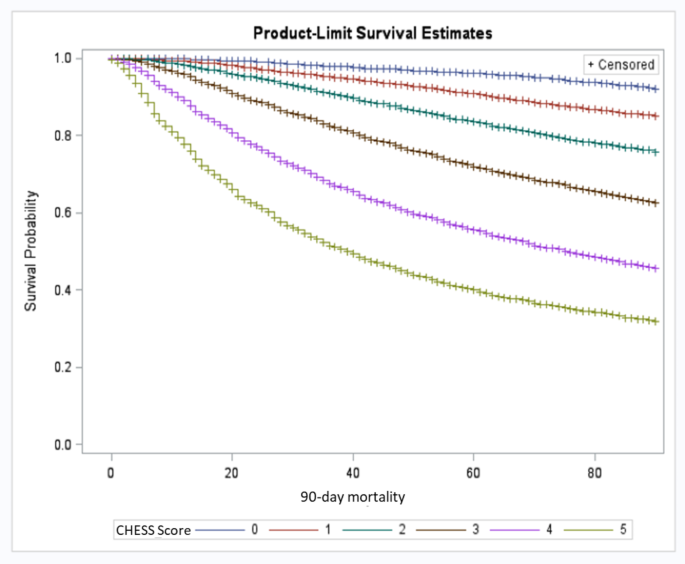 The interRAI CHESS scale is comparable to the palliative performance scale in predicting 90-day mortality in a palliative home care population, BMC Palliative Care11 abril 2025
The interRAI CHESS scale is comparable to the palliative performance scale in predicting 90-day mortality in a palliative home care population, BMC Palliative Care11 abril 2025 -
 Test Your Chess I.Q.11 abril 2025
Test Your Chess I.Q.11 abril 2025 -
Chess Ranking System: A Complete Guide11 abril 2025

você pode gostar
-
 Escolha de Rei e Rainha marca o início da programação da 50ª edição dos Jogos da Primavera, Notícias, Esporte11 abril 2025
Escolha de Rei e Rainha marca o início da programação da 50ª edição dos Jogos da Primavera, Notícias, Esporte11 abril 2025 -
 File:Intercable Arena (Innenansicht) beim Eröffnungsspiel.jpg - Wikimedia Commons11 abril 2025
File:Intercable Arena (Innenansicht) beim Eröffnungsspiel.jpg - Wikimedia Commons11 abril 2025 -
 Seleção brasileira de basquete 3x3 durante os Jogos Mundia…11 abril 2025
Seleção brasileira de basquete 3x3 durante os Jogos Mundia…11 abril 2025 -
 Belle Delphine defends 'kidnap' pics after star is accused11 abril 2025
Belle Delphine defends 'kidnap' pics after star is accused11 abril 2025 -
 What's On Steam - Microsoft Flight Simulator11 abril 2025
What's On Steam - Microsoft Flight Simulator11 abril 2025 -
 Baixar Os Jovens Titãs 1ª a 5ª Temporada MP4 Dublado – Baixar11 abril 2025
Baixar Os Jovens Titãs 1ª a 5ª Temporada MP4 Dublado – Baixar11 abril 2025 -
 Anime Dimensions Simulator Script Hack - Auto Dimension, Auto Raid11 abril 2025
Anime Dimensions Simulator Script Hack - Auto Dimension, Auto Raid11 abril 2025 -
Escola Games11 abril 2025
-
 Sprinkler Freeze Dance – joyful parenting11 abril 2025
Sprinkler Freeze Dance – joyful parenting11 abril 2025 -
 4K Wallpaper Expert - Apps on Google Play11 abril 2025
4K Wallpaper Expert - Apps on Google Play11 abril 2025
